Loading...
前言
本文采用前后端分离模式,后端给前端每个分片的上传临时凭证,前端请求临时 url,通过后端间接的去上传分片。前端分别提供了 vue3 (TypeScript)和 react(TypeScript) 版本的示例,代码逻辑保持 99% 一致,差异仅仅是为了适配两个框架不同组件库 API 的差异。
前端 React:React + TypeScript + Antd + axios + spark-md5 前端 Vue:vue@3.4 + TypeScript + arco design vue + axios + spark-md5后端:Springboot 3.x + minio + mybatisplus + redis + lombok + hutool-core
前后端的依赖都是截止 2024.05 的最新版。代码较多,文章内只讲实现思路,gitee 地址: https://gitee.com/jsonqi/minio-spring-web
为什么不直接前端对接 minio,而要走后端?
- 直接在前端搭建 minio 环境,如果后端给临时凭证让前端直传,后端是无法感知到文件的存入和变动
- 大文件是必须要入数据库的,否则秒传是无法实现的。
为什么要给前端每个分片的 url 上传,而不是前端将每个分片给后端,后端存入 minio?
- 若让前端每个分片都请求后端,后端再将分片传给 minio,势必会造成带宽占用和增大服务器压力
- 后端生成的分片 url 也是临时凭证 url,可以将时效性尽量降低,来确保文件服务器的安全性。(若对安全性有及其严格的考究另说)
上传
功能点
- 文件入库(秒传)
- 分片上传,以全量文件计算 md5。
- 识别
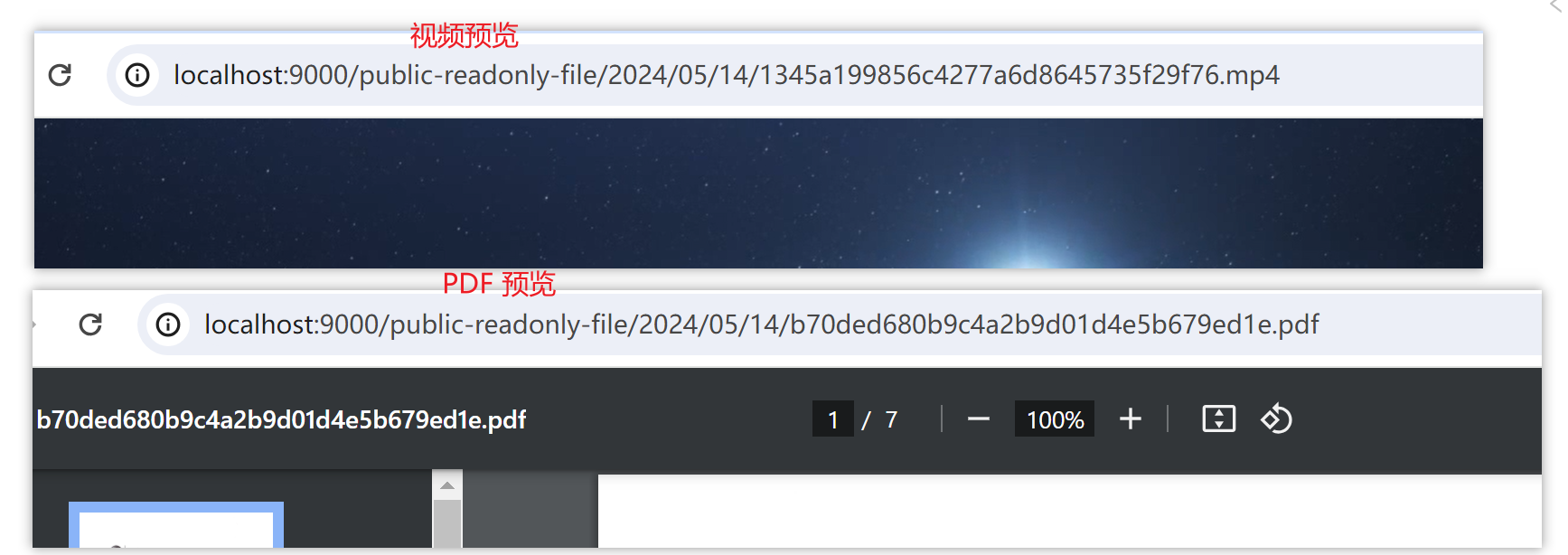
ContentType,可以在线访问浏览器支持的文件格式,如:图片、视频、PDF 等。 - 进度条展示。如果不想使用自定义进度条,直接把文件地址放到 a 标签中下载即可
- 文件重命名以原文件名 + md5 格式重命名。尽可能在文件名不重复情况下,保留原文件名。
功能效果图
展示及请求
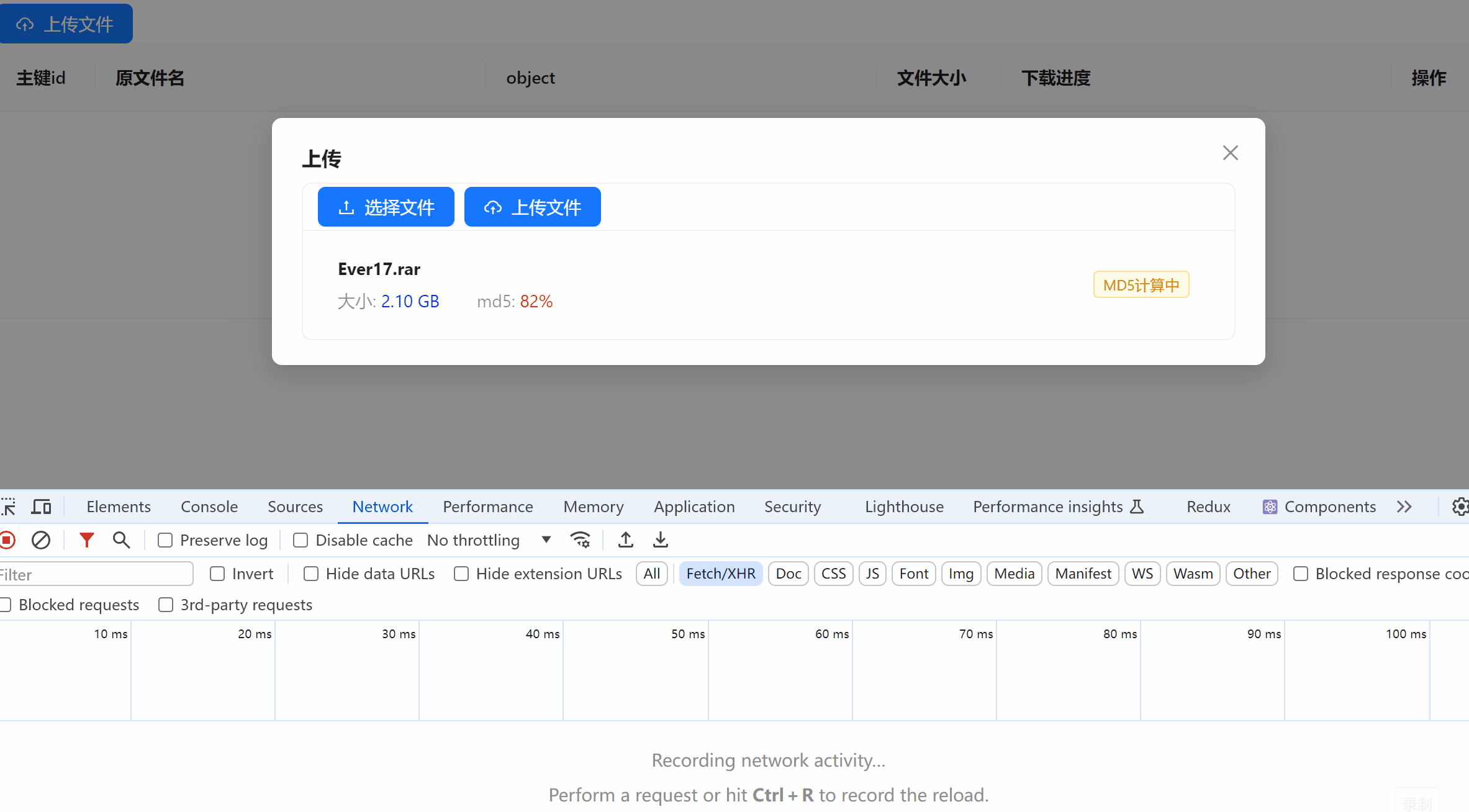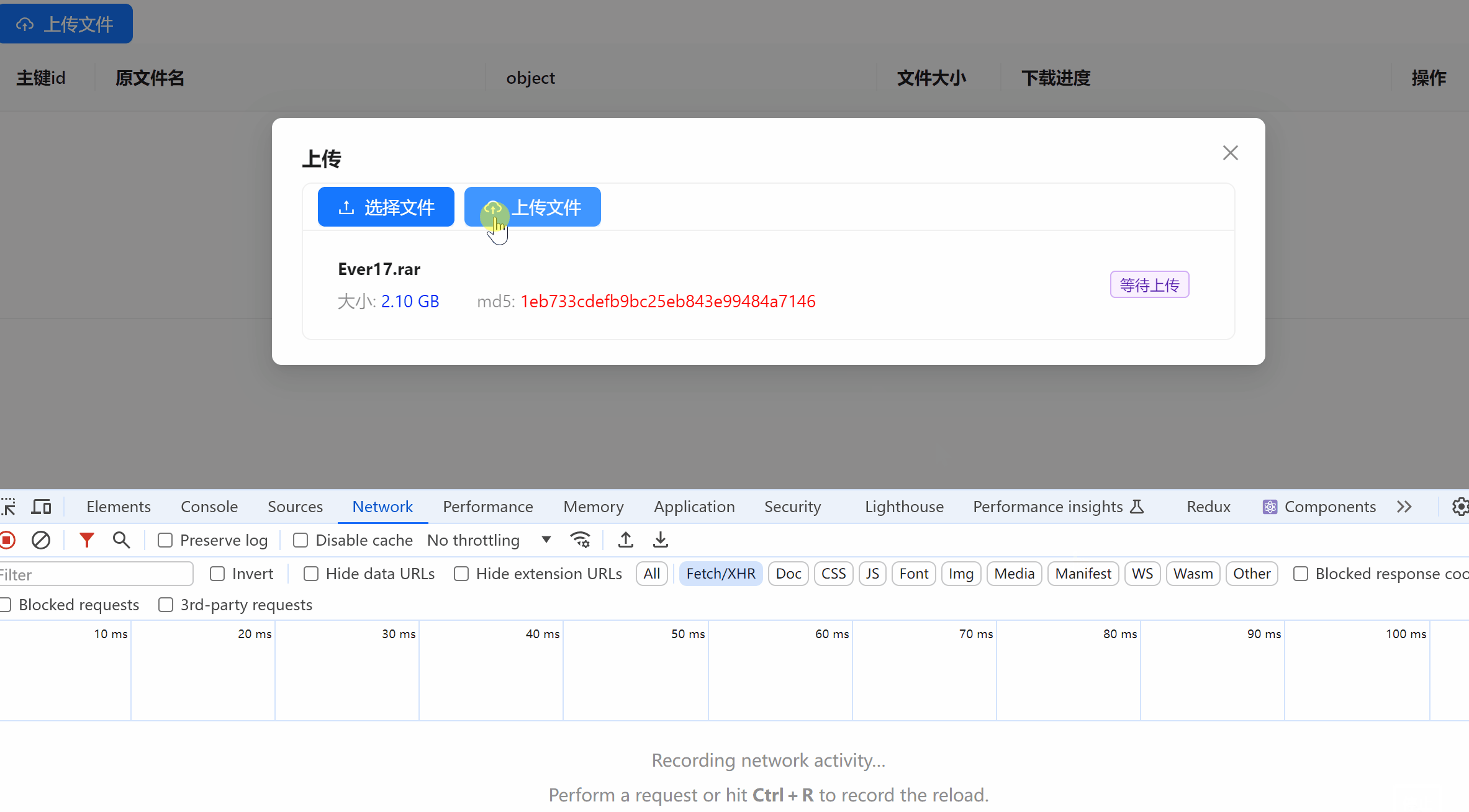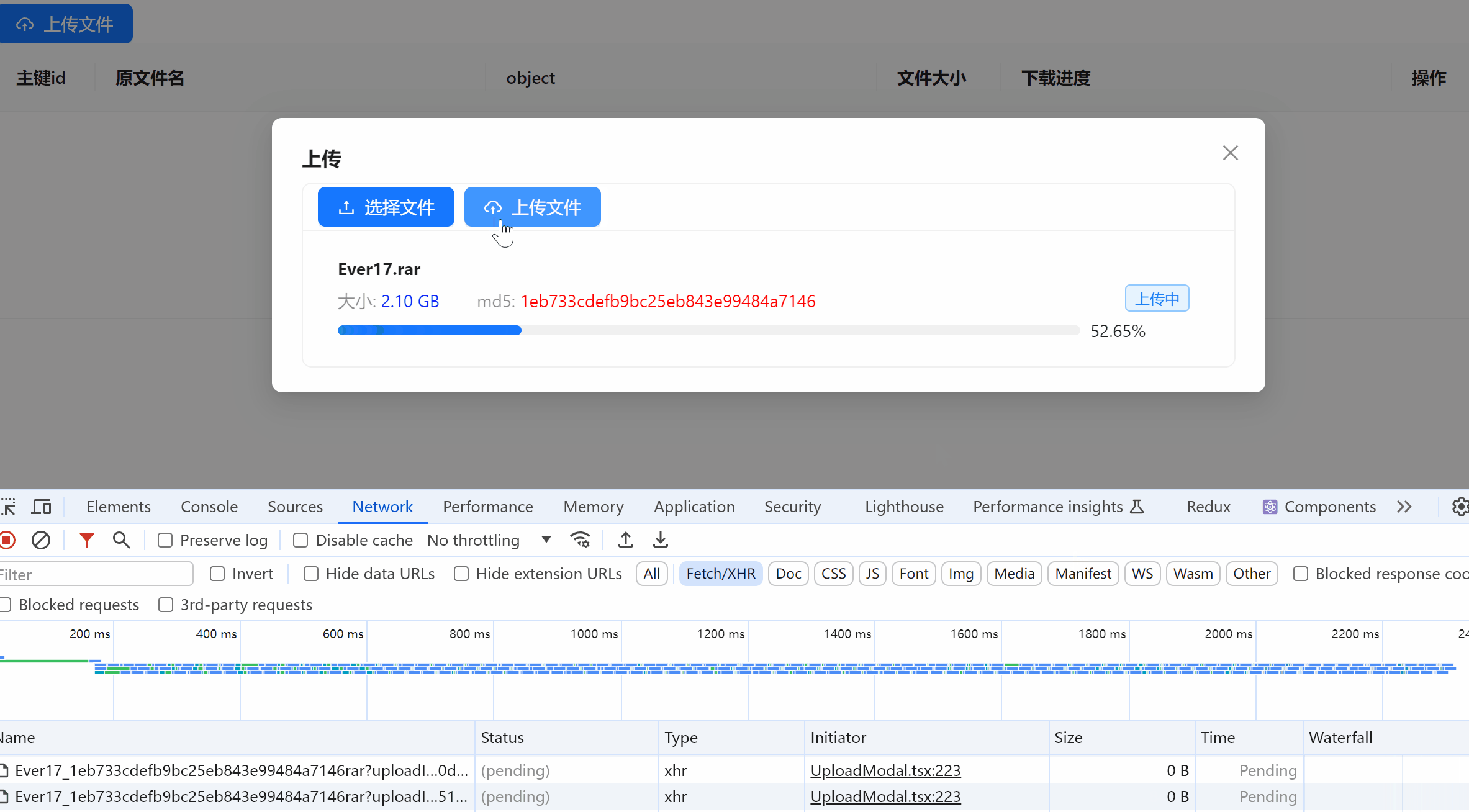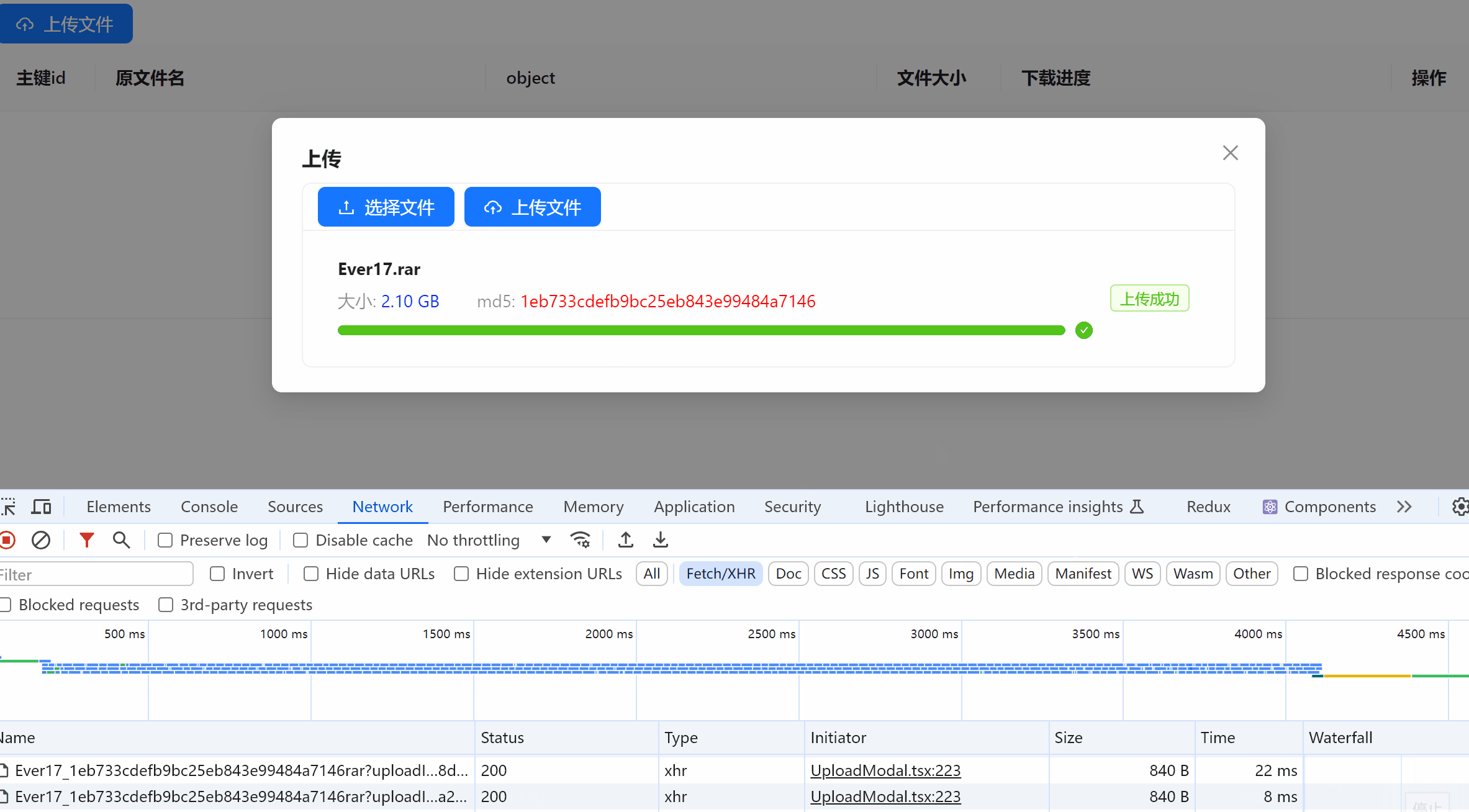
前端控制台

浏览器可支持的文件预览
目录结构
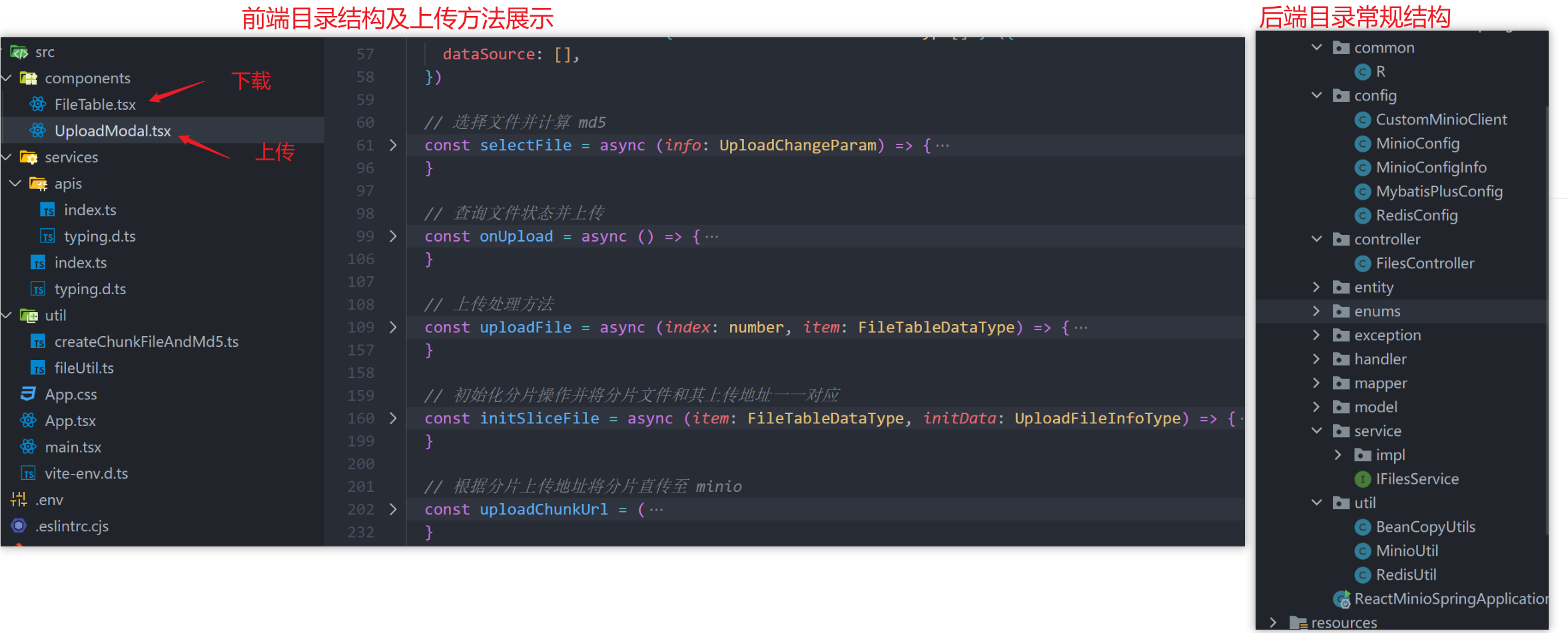
一个文件的上传,对接后端的请求有三个
- 点击上传时,请求
<检查文件 md5>接口,判断文件的状态(已存在、未存在、传输部分) - 根据不同的状态,通过
<初始化分片上传地址>,得到该文件的分片地址 - 前端将分片地址和分片文件一一对应进行上传,这步直接对接 minio
- 上传完毕,调用
<合并文件>接口,合并文件,文件数据入库
大文件分片流程
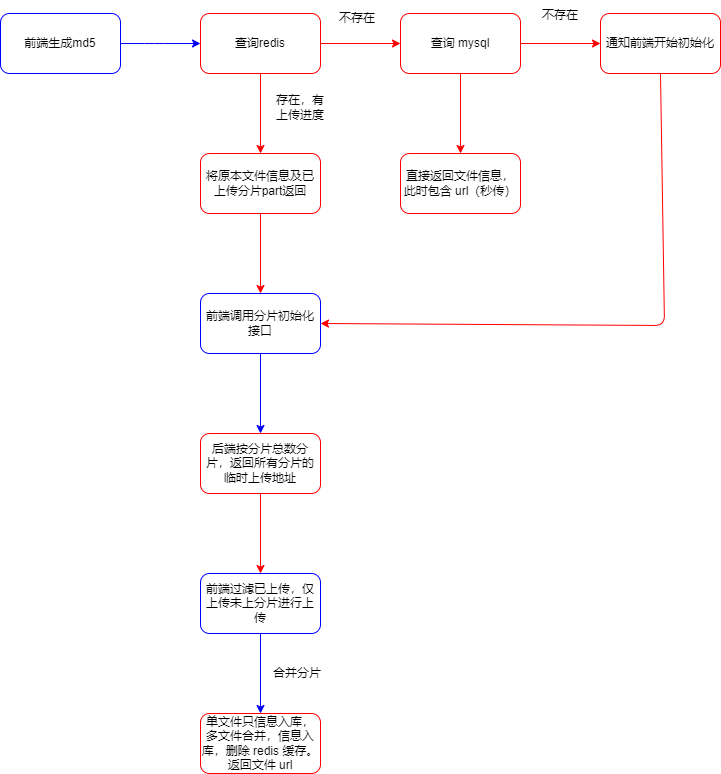
整体步骤:
- 前端计算文件 md5,并发请求查询此文件的状态
- 若文件已上传,则后端直接返回上传成功,并返回 url 地址
- 若文件未上传,则前端请求初始化分片接口,返回上传地址。循环将分片文件和分片地址一一对一应
- 若文件上传一部分,后端会返回该文件的
uploadId(minio 中的文件标识)和listParts(已上传的分片索引),前端请求初始化分片接口,后端重新生成上传地址。前端循环将已上传的分片过滤掉,未上传的分片和分片地址一一对应。 - 前端通过分片地址将分片文件一一上传
- 上传完毕后,前端调用合并分片接口
- 后端判断该文件是单片还是分片,单片则不走合并,仅信息入库,分片则先合并,再信息入库。删除 redis 中的文件信息,返回文件地址。
该 bucket 开启了公共只读,所以链接地址是可以直接后台拼接的。如何开启公共只读,可参考文章:MinIO 基础 api
前端优化点
- 计算 md5 的任务可以放在 webworker 中进行,不会影响主线程
- 超大文件计算 md5 耗时极长,可以适当抽取文件的部分分片进行计算,但要保证该文件的唯一标识,这个没有特别好的优化方法。
大文件 md5 计算耗时优化(更新)
大文件在全量计算 md5 的情况下,耗时很长,所以之前添加了进度来显得不那么单调,此次优化项
- 多线程计算 md5
- 根据文件分片的 md5 使用默克尔树的树根作为整个文件的 md5,技术来源:https://juejin.cn/post/7353106546827624463
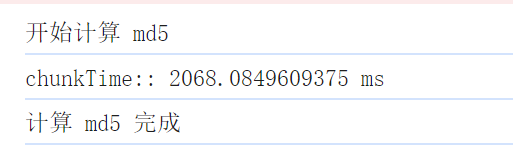
未优化前,一个 2.1G 的文件上传耗时 18s
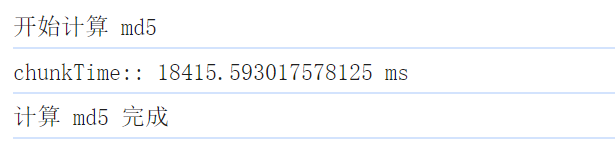
优化后,仅 2s
缺点
作者也说得很清楚,默克尔树 依赖于分片的 md5,分片大小改变会导致分片的 md5 改变,最终导致文件的 md5 和之前不同,采用此方法的前提是:分片大小不会轻易更改,否则慎重使用,至于哈希碰撞的情况,没有大量数据无法实测
下载
下载时,比如附件这种,前端是循环渲染出来的,展示的也是原文件名,该数据的信息都知道。请求后台下载接口时,尽量不要使用文件名,而使用主键 id 去获取文件
效果图展示
下载及暂停操作展示
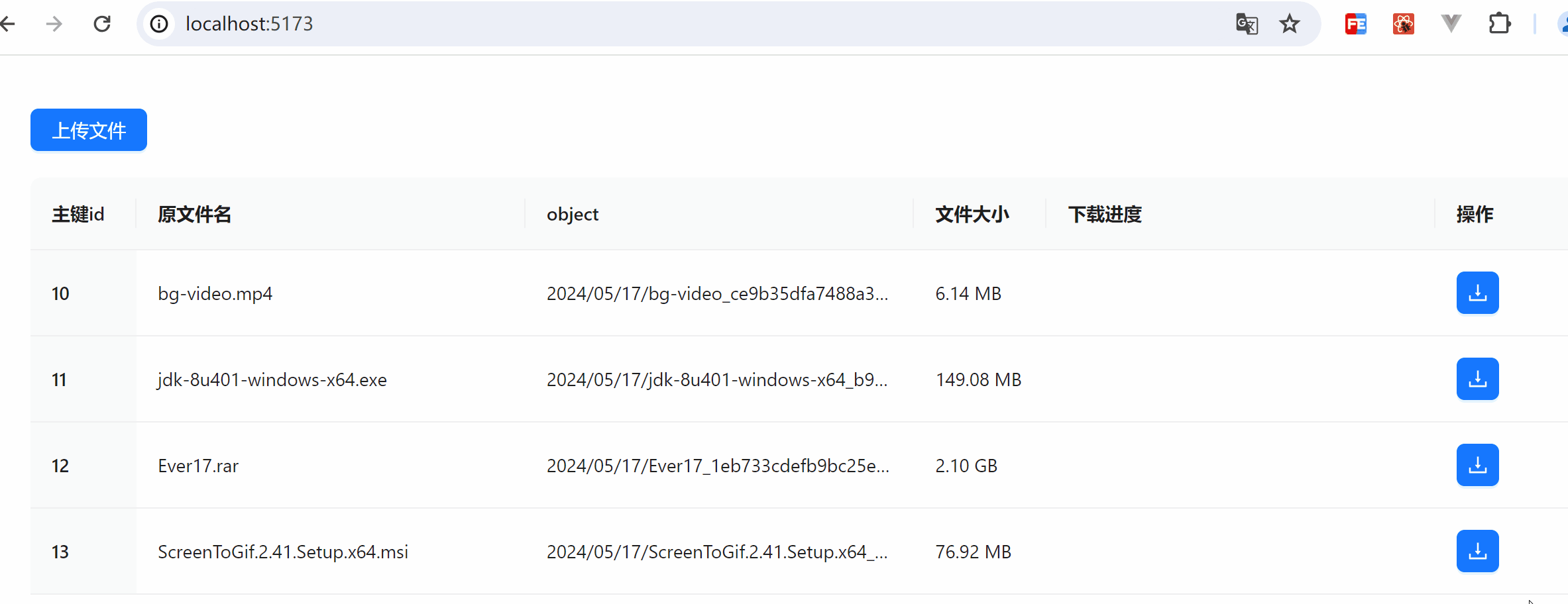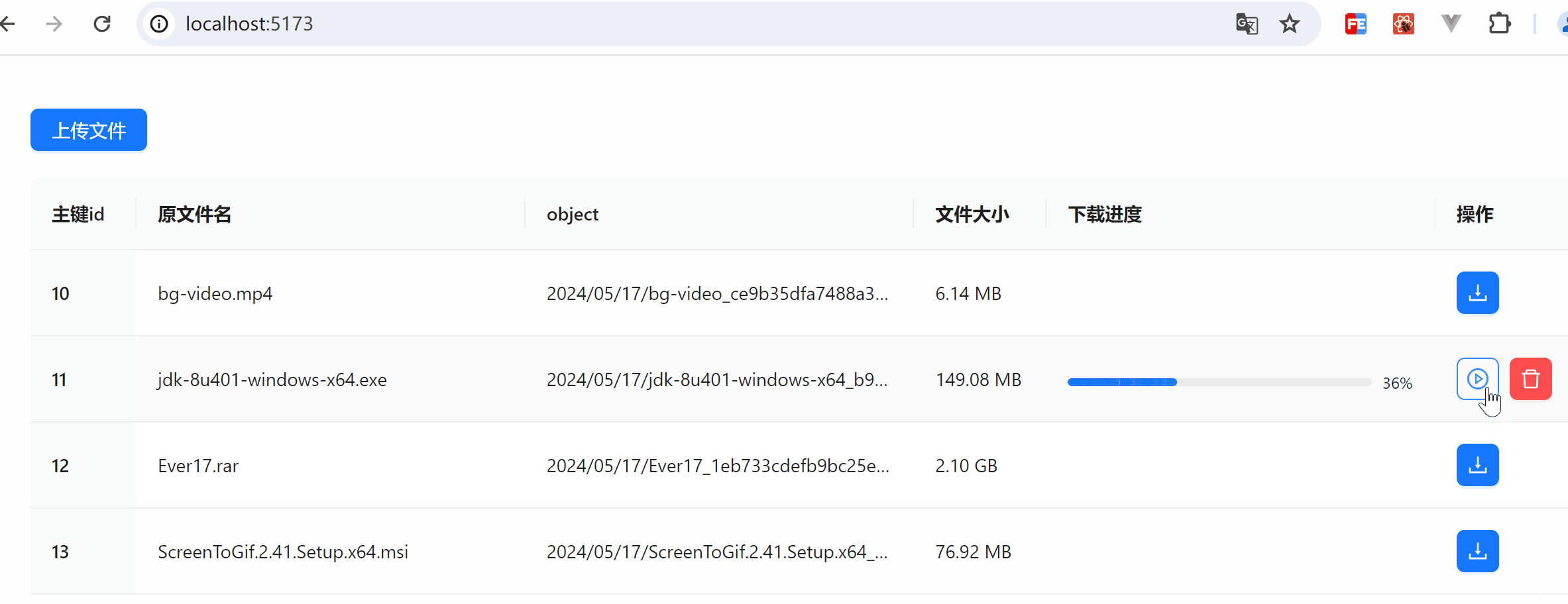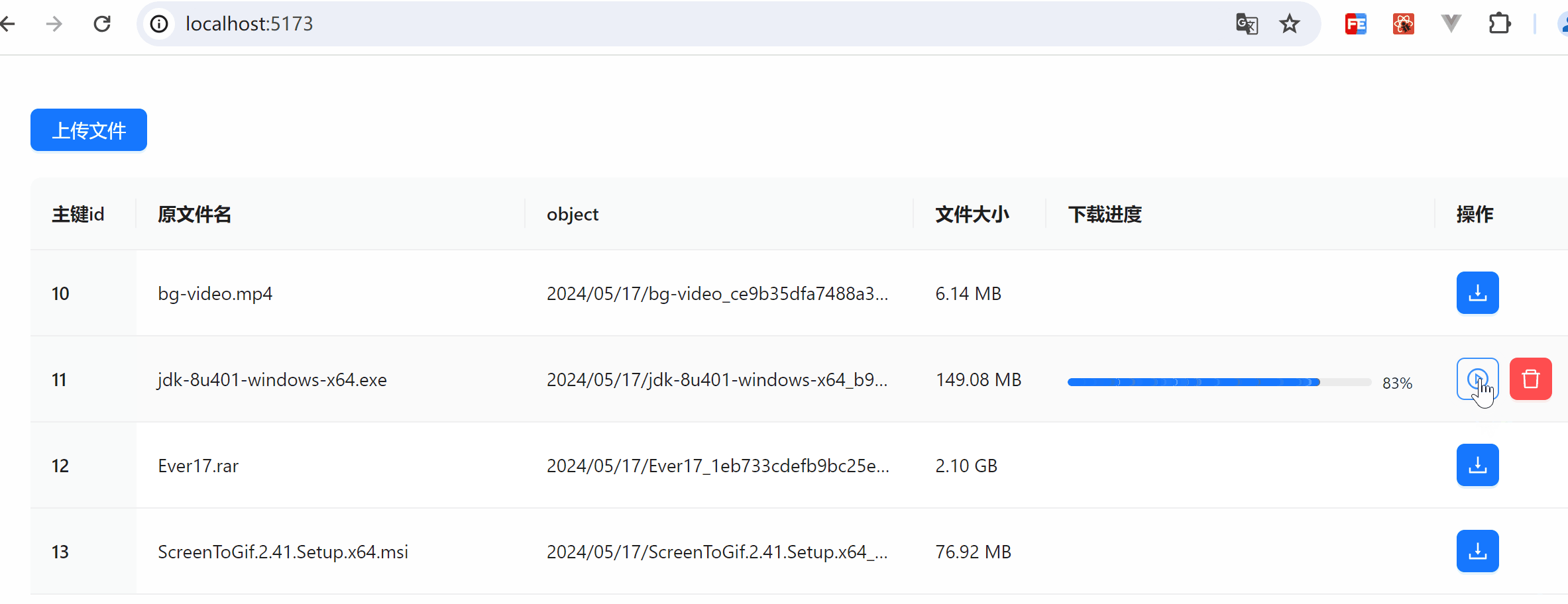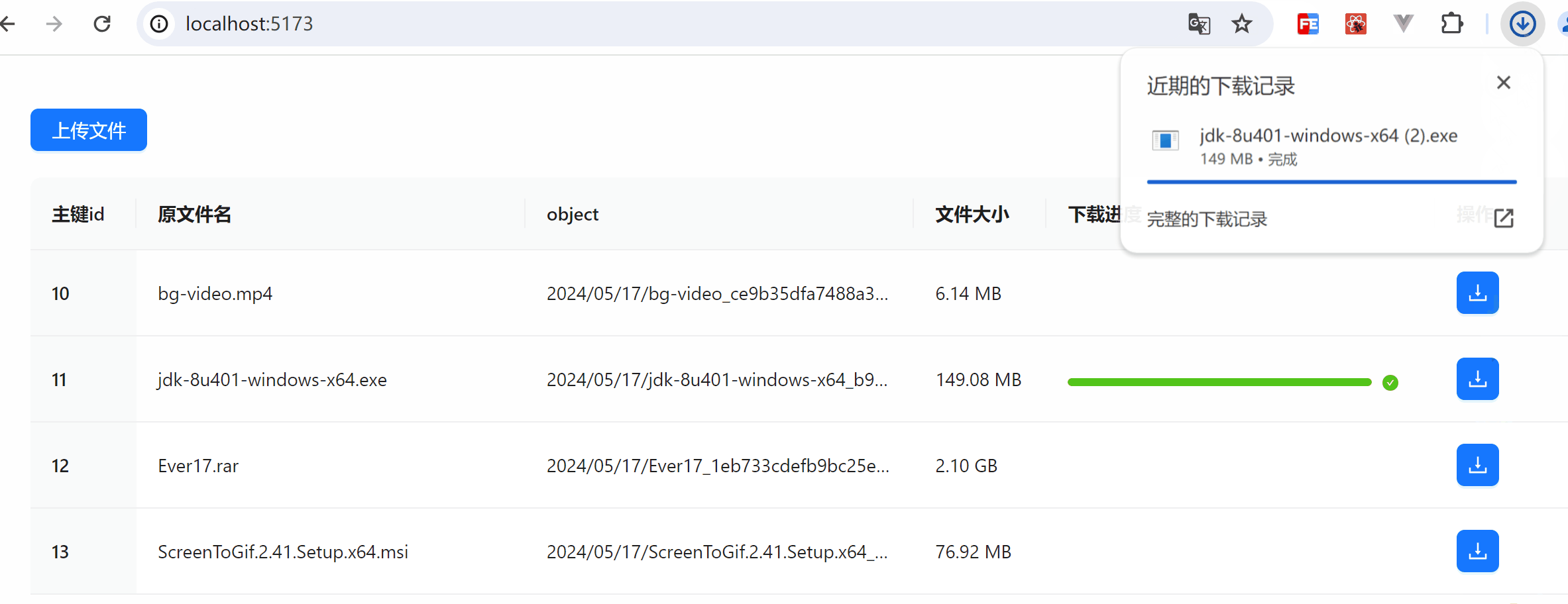
下载内容展示
